Category: Tecnologia
-
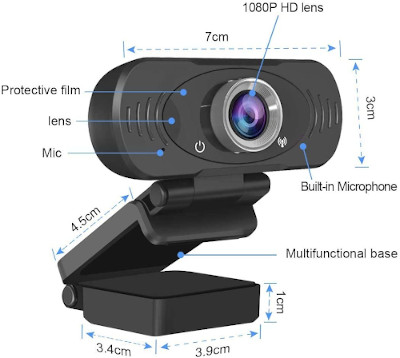
Recensione webcam per lezioni online
Perché una nuova webcam? Non sappiamo ancora con certezza come si farà lezione a settembre, quando le scuole riapriranno. Qualcuno andrà a scuola, qualcuno farà lezione online, qualcuno farà i turni. Quello che sappiamo è che il Covid-19 non è ancora stato debellato e che molto probabilmente sarà ancora fra noi il prossimo anno scolastico.…
-
Compiling Courier-MTA from sources on Debian buster/sid
Updated on October 23, 2019, for the Debian GNU/Linux Buster release. This aims to be a complete, but not necessarily friendly guide, at least as of today. It contains a list of commands and actions I used to compile Courier-MTA from sources on a very basic Debian stable/testing/sid instance (e.g. a mix of stable, testing and…
-

Nobody Oracle
Now this is for real nerds only. And you need to know a bit of good music in order to understand the wit. Only less than 1% of people understand all the references in this song, but there’s a walkthrough for others at the end… Music by Roger Waters (Pink Floyd) Lyrics by me I’ve…
-
Windows 10, le novità. Beh, quasi.
Il 29 luglio Microsoft rilascerà la nuova versione di Windows. Su questo blog la cosa è probabile che interessi poco, ma ci tenevo ad elencare le novità giusto per non perdere d’occhio in che direzione sta andando il mondo desktop. Commento le novità seguendole una per una alla pagina ufficiale MS. Windows 10 avrà il…
-
AutoCloseable EntityManager
Sembra che io non sia l’unico a chiederselo e sembra anche che le risposte date non siano necessariamente soddisfacenti. Non sarebbe bello poter usare il try-with-resources con gli EntityManager? Pare che il motivo per cui EntityManager non implementa AutoCloseable sia che se lo facesse, potrebbe solo fare la close() di sè stesso, ma non la…
-
Sviluppo di applicazioni web in team
Le pagine di un sito dinamico che ha sia una forte componente di business logic, sia dei precisi requisiti estetici e comunicativi, devono necessariamente essere sviluppate da più persone, ognuna nel proprio ambito di competenza. Lo sviluppo contemporaneo dei due aspetti, comunicativo e funzionale, è però problematico, indipendentemente da quale linguaggio usino i programmatori e…
-
L’anno di Linux sul desktop sarà il 2096.
Microsoft cesserà il supporto di Windows XP a breve. Io nel 2006 scrivevo che quello era l’anno di Linux sul desktop (non su questo blog). In quell’anno qualcosa era cambiato, in effetti, probabilmente grazie alla crescente popolarità di Ubuntu. Siamo però ormai nel 2013 (2014 fra qualche ora) e ci chiediamo ancora quando sarà l’anno…
-
Eccezioni: prevedere l’imprevedibile.
Sale qb. Questa è la parte più antipatica di ogni ricetta di cucina per chi non ha esperienza di cuoco. Di solito arriva al fondo dell’elenco ingredienti. Cosa significa qb? Beh sì, significa “quanto basta”, ma a quanto corrisponde? Potremmo dire che il calcolo del valore della variabile qb procede per approssimazioni successive: 1. Assaggia…
-
Tipizzazione forte, oltre lo scripting
Apro, con questo articolo, una serie di suggerimenti sulla programmazione. Non è un corso, è una collezione di informazioni sperabilmente utili. Userò del codice Java quando sarà necessario fare esempi, ma esporrò concetti validi in tutti i linguaggi. Partiamo. Quale differenza passa fra Java e JavaScript? A parte i nomi somiglianti ed una sintassi simile,…